A gentle introduction to Hadoop
status: completed
Introduction
This article aims to simplify and make Hadoop less cooler by understanding the overall purpose and working of a file system. We will first discuss why we care about Big Data and why need a file system to store the large amounts of data that is generated. We will then discuss a simple analogy for hadoop to understand the overall idea behind it, followed by explaining the individual components in HDFS.
Why do we care about Big Data ?
Consider the following facts:
- Humans and human created systems generate a lot of data.
- 95% of the new data was generated between 2010- 2016
As data storage technology improved, so did the we start to store all kinds of data- logs, text, video, audio, images.
To summarise, we characterize Big data by the following features.
- Volume- The quantity of the generated data.
- Velocity- The speed at which data is generated and processed to meet the demands.
- Variety- The type and nature of data
We also talk about veracity indicating the quality of the data captured.
Data is knowledge and knowledge is wealth. If Machine learning models are a vehicle, then the fuel that drives the vehicle is data. Thus there is a need to build a cheap and efficient file system architecture that can help in fast accessibility and retrieval of data. Hadoop is one such architecture.
Bob and the magic godown: An anology for Hadoop
Consider farmer Abe cultivating rice and has a storage space in his house to store his yield. But the storage space is enough just to store yield of 100 sacks while on a good year he can end up with a yield more than 300 to 500 sacks. He would now have to approach the magic godown whose owner Bob is a friend to store the excess yield. Bob maintains a book with the details of room capacity and a team of elves in charge of each of the rooms in the godown. He offers to store all of Abe’s yield. The magic in the godown is that it can create 2 replicas of the stock that is brought to it. This is because Bob knows that his team of elves can sometimes be inefficient and therefore makes multiple copies of the stock.
Two months later Abe wants 20 sacks of rice from the godown to make rice noodles and he goes to the godown. Bob knowing that the godown is capable of magic, asks for the recipe for the rice noodles and gives it to the godown elves. The godown elves apply the recipe to the sacks of rice placed at different rooms individually and ask the elder elf to combine all of the rice noodles into a single container. The rice noodle is combined and shipped to Abe.
What is HDFS?
HDFS or Hadoop File System lets you store large amounts of data (read petabytes, zetabytes) on a scaleable and cost-efficient collection of nodes (cluster of consumer computers AKA commodity hardware). Hadoop is designed to prevent data loss while also being efficient at providing fast access to data.
Hadoop also follows the write-once-read-many model, which simply means that data once stored is not altered but only read many times for performing tasks or executing various commands. Commands that are to be executed on the data are handled using the MapReduce processing model.
Hadoop File System has 5 components or services under 2 main categories of functions.
- Master Services
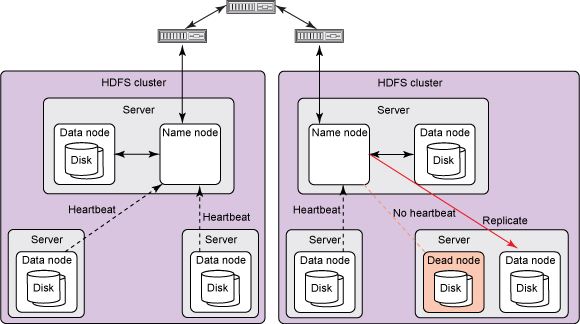
- Name node (Bob): Manages the data block management.
- Secondary Name node: Works concurrently with Name node.
- Job Tracker (Elder Elf): Tracks the status of the jobs.
- Slave services
- Data node: Commodity hardware nodes which provide storage. Data nodes send heartbeat to Name node indicating their functioning status. The interval for these heartbeats vary but is usually in the range of 3 seconds.
- Task tracker
Process overview
Based on the analogy, lets go through the sequence of steps of storing and retrieving data from the Hadoop File System.
-
For instance consider a file that includes phone numbers of everyone in the world entered alphabetically; The numbers of alphabet ‘A’ are stored on server 1 and ‘B’ on server 2 etc.
-
To ensure availability when any of the nodes fail, HDFS makes 2 replicas of the data and now has to find space in its storage capacity to store the data. (Known as Redundancy or fault tolerance)
-
The cluster contains two different types hardware systems- first, the commodity hardware (usually referred to as SATA) and a second, more advanced, reliable and optimized storage hardware(usually SAS disks). The HDFS runs as a layer on top of the commodity hardware to manage incoming data. This article explains the differences in the hardware well.
-
HDFS uses the advanced hardware to store ‘metadata’ or data about data on the location description of the incoming data. For instance, the incoming 100 TB of the data could be distributed among 5 machines and this information about the distribution would be stored in the advanced hardware.
-
The cluster stores data in blocks. Blocks are the smallest unit of data in HDFS. Each block have a size of 64 MB. HDFS tries to place each block (of the given data) on separate nodes(data nodes). The file creation process uses a staging mechanism where the data to be written to HDFS is temporarily stored locally until enough data accumulates for a block. Once that accumulation is complete the Name node commits the data to be written to disk.
The Mapreduce algorithm
In 2004, Google came up with the MapReduce algorithm to effectively process queries on large data repositories. It enables scalability across large Hadoop clusters. The MapReduce paradigm is a collection of two separate distinct tasks that programs perform.
-
Map: This job takes in a set of data and converts it into another set of intermediate data. Data is stored as key-value pairs.
-
Reduce: The out of Map task is combined to give a smaller set of tuples.
An example for MapReduce
Consider the task of finding the population of a state by the Census bureau. Each volunteer is sent to a set location and is asked to collect the population information. The data they collect is stored as (location, population) tuples with the location being the key. They then report to the capital city where the bureau collects the information and adds up all of them to give the population of the state.